HBase
Apache HBase™ is the NoSQL database, a database built on top of Hadoop and HDFS File System. A distributed, scalable, big data store.
It's commonly called as key-value store, a column-family-oriented database, a versioned maps of maps database.
Why HBase
- My system has well normalized SQL database, however the tables have grown huge, queries require table joins and it takes lot of time.
- My system needs to perform random reads on a large SQL table. The queries are consuming more time. The buffering is not much helpful due to the random reads.
- Addition and removal of entities in SQL tables is becoming frequent, due to the large nature of the tables, the maintenance cost is increasing.
- The tables are growing rally big, I can't manage the storage requirement with the commodity hardware, I may have to upgrade to super/specialized computers.
HBase
- Allows fast random reads and writes.
- Although HBase allows fast random writes, it is read optimized
- Built on top of Hadoop system which solves the horizontal scaling issue.
- HBase is a NoSQL database, loosely coupled and no joins.
- Is good for large/sparse data sets.
- HBase assures Consistency and partion tolerance of CAP theorem.
HBase Examples
- Finding the 50 largest items in a group of 2 billion records
- Finding the non-zero items representing less than 0.1% of a huge collection
- Messaging Platform
Who is using HBase
http://radar.oreilly.com/2014/04/5-fun-facts-about-hbase-that-you-didnt-know.htmlHBase Architecture
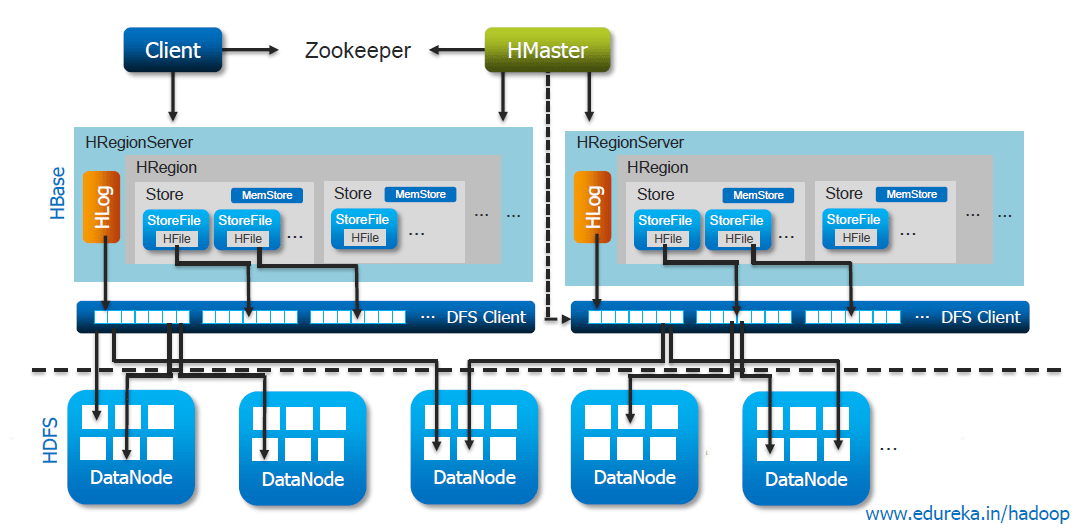
Key components of Hbase?
- Zookeeper: It does the co-ordination work between client and Hbase Maser
- Hbase Master: Hbase Master monitors the Region Server
- RegionServer: RegionServer monitors the Region
- Region: It contains in memory data store(MemStore) and Hfile.
- Catalog Tables: Catalog tables consist of ROOT and META
HBase operational commands
- get
- put
- scan
- increment
- delete
HBase and Hadoop
- Fast random reads require the data to be stored structured (ordered).
- The only possibility to modify a file stored on HDFS without rewriting is appending.
- Fast random writes into sorted files only by appending seems to be impossible.
- The solution to this problem is the Log-Structured Merge Tree (LSM Tree).
- The HBase data structure is based on LSM Trees
The Log-Structured Merge Tree
The LSM Tree works the following way- All puts (insertions) are appended to a write ahead log(WAL) (can be done fast on HDFS, can be used to restore the database in case anything goes wrong)
- An in memory data structure (MemStore) stores the most recent puts (fast and ordered)
- From time to time MemStore is flushed to disk.

- This results in a many small files on HDFS.
- HDFS better works with few large files instead of many small ones.
- A get or scan potentially has to look into all small files. So fast random reads are not possible as described so far.
- That is why HBase constantly checks if it is necessary to combine several small files into one larger one
- This process is called compaction. There are two different kinds of compactions.
- Minor Compactions merge few small ordered files into one larger ordered one without touching the data.
- Major Compactions merge all files into one file. During this process outdated or deleted values are removed.
- Guarantees on the maximum number of compactions per entry can be made because of the way HBase triggers compactions.
- Bloom Filters (stored in the Metadata of the files on HDFS) can be used for a fast exclusion of files when looking for a specific key.
HBase Vs MySQL
http://www.slideshare.net/cloudera/chicago-data-summit-apache-hbase-an-introduction

HBase Schema design
By now we know in theory what and when to use HBase. Let me try to solve some of the most commonly solved industry problems using HBase.
Twitter: User Follows and Followers.
Let’s try to build the schema for handling the twitter “Follows and followers” use case.
The schema should help us to answer some basic queries like
- List all the users following a user
- List all the users who follows a user
- Give me the personal details of a user
Table: UserFollows
Row key => userId
Column Family: PersonalInfo, Follows

The table UserFollows uses the userID as the rowkey. It maintains two column families
PersonaInfo: To maintain all the personal details of a user
Follows: List of all the userId's followed.
This tables should help us to answer query [1] and [3], however the same table can't be used to answer [2], since it needs full table scan for answering each query. This would be very expensive.
So how do we address this issue ?
How about another table which maintains the Followed by relation ship, take a look at below table "UserFollowed"
Table: UserFollowed
Row key => userId
Column Family => FollowedBy

This table can easily answer query [2]. So with these tables we are able to answer all the queries.
Do you see any issue with these tables ?
- Data redundancy ?. Yes. However, it's important to note that only the row keys are indexed, for faster reads and writes it's still ok, if we end with data redundancy.
Since it's only the rowkey which is indexed, we can futher optimize by including the followers users within the rowkey. Example
"@anil+@sunil"
"@anil+@john"
In this way it becomes faster to scan through the indexed data and find who follows whom.
Flipkart: Sellers Catalog
TBDMonitoring: IT Infrastructure Monitoring
TBD
References
Apache HBaseYMC
https://en.wikipedia.org/wiki/Apache_HBase
http://career.guru99.com/top-13-hbase-interview-questions/
http://www.edureka.co/blog/overview-of-hbase-storage-architecture/
SCOM 2012 Online Training Institute
ReplyDeleteSap MM Online Training Institute
SQL and PLSQL Online Training Institute
Sap BW Hana Online Training Institute
very nice article
ReplyDeleteBest Splunk Online Training
Best SCOM 2012 Online Training
Best Sap MM Online Training
Best SQL and PLSQL Online Training
Best Sap BW Hana Online Training
Your post is very great.I read this post. It's very helpful.Cheers for sharing with us your blog.
ReplyDeletePython training in Noida
https://www.trainingbasket.in