I found most of the basic information of OpenTSBD from the internet. However I took some time to understand the table schema and also the way the uid mapping is done and used across tables.
As of OpenTSDB 1.x there are 4 tables:
hbase(main):001:0> list
TABLE
table-name
tsdb
tsdb-meta
tsdb-tree
tsdb-uid
Let's understand the two most important tables 'tsdb-uid' and 'tsdb'.
Consider a write operation using telnet
'put sys.mem 1234567890 host=host1.comp.inc.com'
Here
sys.mem is the metric name
1234567890 is the time stamp
host is the tag1 name
host1.comp.inc.com is the tag1 value
Let's consider following uids mapped to each names
sys.mem => x00x00x01
host => x00x00x01
host1.comp.inc.com => x00x00x01
The tsdb-uid shows the name to uid and the uid to name mapping.

The rowkey is composed of
3 bytes : metric uid
4 bytes : metric uid. The timestamp rounded to the nearest hour. Example: 12:32 is rounded to 12:00.
3 bytes : tag1 name uid
3 bytes : tag1 value uid
row key = metric uid + partial time + tag1 name uid + tag1 value uid
row key = x00x00x01 + 12:00 + x00x00x01 + x00x00x01
The key name for the columnfamily 't' contains the precise timestamp from the rounded time. Example 12:32 is rounded to 12:00, so the remaining seconds 32 is the value for the 't'
Let's see how this looks in the 'tsdb' table

To summarize:
Row key is a concatenation of UIDs and time:

As of OpenTSDB 1.x there are 4 tables:
hbase(main):001:0> list
TABLE
table-name
tsdb
tsdb-meta
tsdb-tree
tsdb-uid
Let's understand the two most important tables 'tsdb-uid' and 'tsdb'.
Consider a write operation using telnet
'put sys.mem 1234567890 host=host1.comp.inc.com'
Here
sys.mem is the metric name
1234567890 is the time stamp
host is the tag1 name
host1.comp.inc.com is the tag1 value
Understanding 'tsdb-uid'
The tsdb-uid maintains the name to uid and uid to name mapping.Let's consider following uids mapped to each names
sys.mem => x00x00x01
host => x00x00x01
host1.comp.inc.com => x00x00x01
The tsdb-uid shows the name to uid and the uid to name mapping.
Understanding 'tsdb'
The tsdb table uses the uids generated for each name and generates the rowkey and the columnfamily key.The rowkey is composed of
3 bytes : metric uid
4 bytes : metric uid. The timestamp rounded to the nearest hour. Example: 12:32 is rounded to 12:00.
3 bytes : tag1 name uid
3 bytes : tag1 value uid
row key = metric uid + partial time + tag1 name uid + tag1 value uid
row key = x00x00x01 + 12:00 + x00x00x01 + x00x00x01
Let's see how this looks in the 'tsdb' table
To summarize:
Row key is a concatenation of UIDs and time:
- metric + timestamp + tagk1 + tagv1… + tagkN + tagvN
- sys.cpu.user 1234567890 42 host=web01 cpu=0 x00x00x01x49x95xFBx70x00x00x01x00x00x01x00x00x02x00x00x02
- Timestamp normalized on 1 hour boundaries
- All data points for an hour are stored in one row
- Enables fast scans of all time series for a metric
- …or pass a row key regex filter for specific time series with particular tags
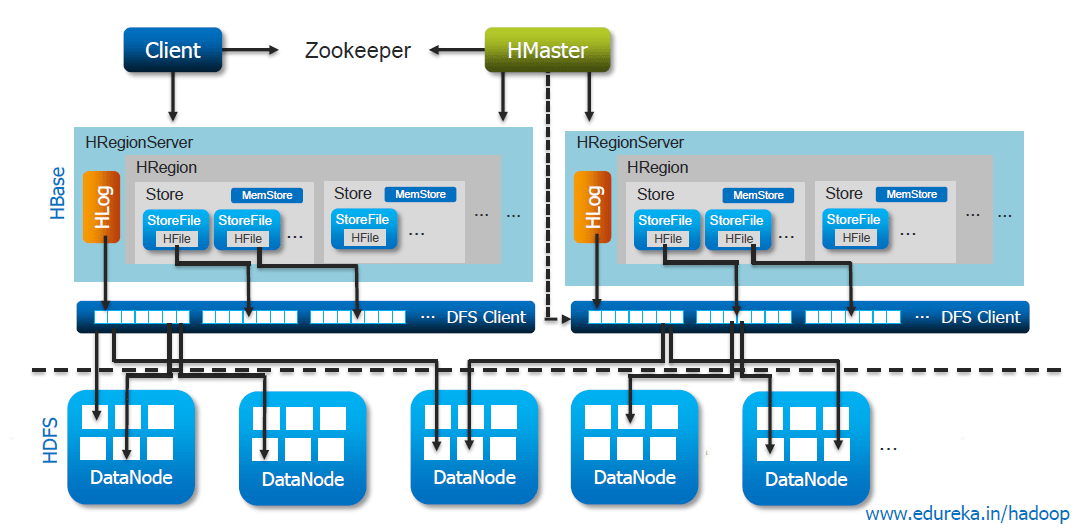
OpenTSDB Architecture
tcollector : A python collection framework used to collect
thousand of metrics from Linux 2.6, Apache's HTTPd, MySQL, HBase, memcached,
Varnish and more. It also posts the data to tsd servers.
asynchbase : A hbase client library used by tsd for all interaction with hbase asynchronously.